
Machine Learning Cheatsheet – Algorithms, Metrics, Formulas

Introduction
Machine Learning (ML) has become one of the most important fields in engineering, computer science, and data science. Whether you’re preparing for BTech exams, revising for placements, or simply learning the basics, a concise and well-structured machine learning cheatsheet can save you hours of study time.
In this cheatsheet, we’ll cover:
- Key machine learning algorithms (supervised, unsupervised, reinforcement learning).
- Essential formulas and mathematical foundations.
- Commonly used evaluation metrics to judge model performance.
- Quick notes, comparison tables, and formulas for fast revision.
By the end, you’ll have a ready-made exam revision sheet to strengthen your understanding and boost your preparation.
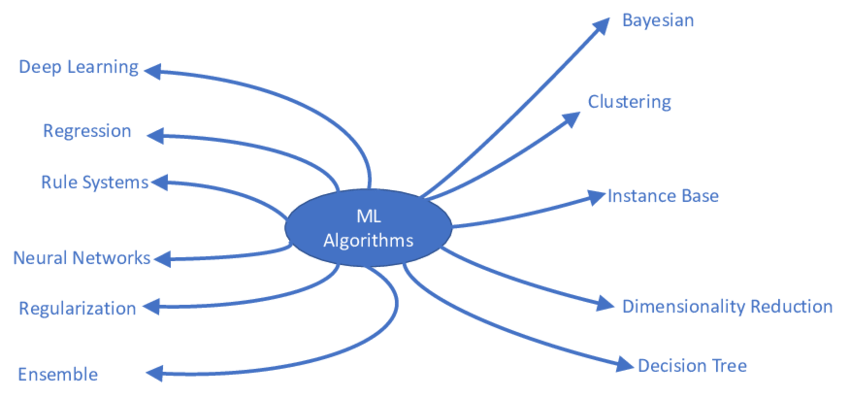
What is Machine Learning?
Machine Learning is a subset of Artificial Intelligence (AI) that enables computers to learn from data and improve their performance without being explicitly programmed.
- Input: Training Data (features + labels)
- Process: Algorithm learns patterns from data
- Output: Predictions, classifications, or decisions
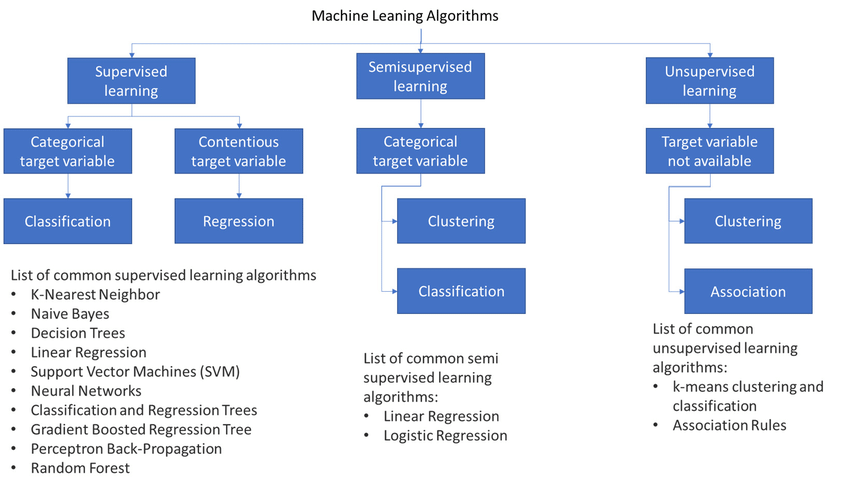
Categories of Machine Learning Algorithms
1. Supervised Learning
Supervised learning uses labeled datasets to train models.
- Regression: Predicts continuous values
- Example: Predicting house prices
- Algorithms: Linear Regression, Polynomial Regression
- Classification: Predicts categorical values
- Example: Spam vs. Non-Spam email classification
- Algorithms: Logistic Regression, Decision Trees, SVM, Naive Bayes
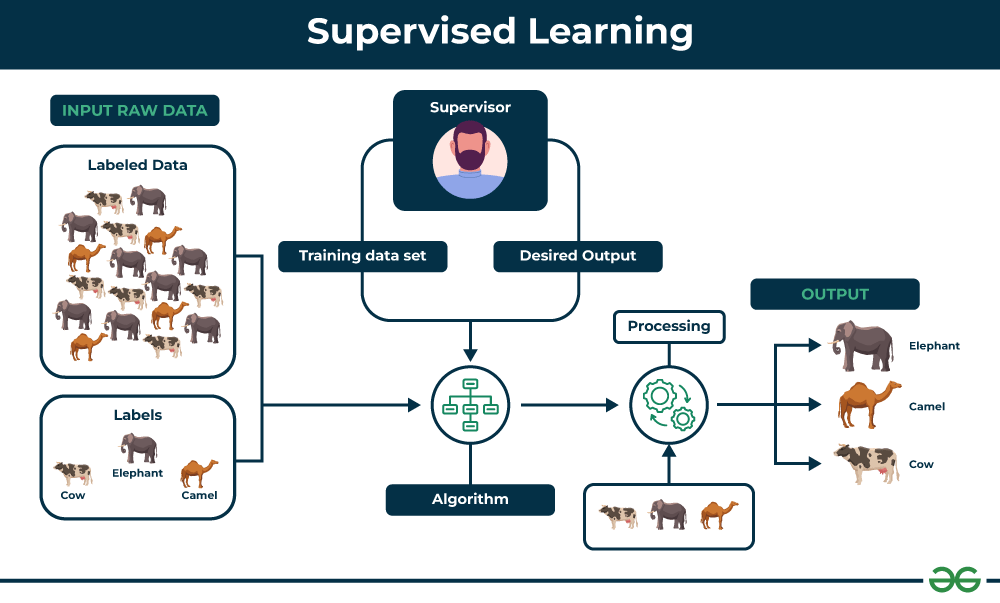
2. Unsupervised Learning
Unsupervised learning deals with unlabeled data, where the algorithm finds hidden patterns.
- Clustering: Grouping similar data points
- Example: Customer segmentation
- Algorithms: K-Means, Hierarchical Clustering
- Dimensionality Reduction: Reducing feature space
- Example: Principal Component Analysis (PCA)
3. Reinforcement Learning
In reinforcement learning, an agent learns by interacting with an environment to maximize rewards.
- Key Concepts: Agent, Environment, Action, Reward, Policy
- Applications: Robotics, Game AI, Self-driving cars
Machine Learning Algorithms Cheatsheet
Regression Algorithms
- Linear Regression
Formula:
y=β0+β1×1+β2×2+…+βnxn+εy = β_0 + β_1x_1 + β_2x_2 + … + β_nx_n + εy=β0+β1x1+β2x2+…+βnxn+ε - Polynomial Regression
Adds higher-order terms to capture nonlinear relationships. - Ridge & Lasso Regression
- Ridge: Adds L2 penalty to coefficients.
- Lasso: Adds L1 penalty, leading to feature selection.
Classification Algorithms
- Logistic Regression
Sigmoid Function:
P(y=1∣x)=11+e−(β0+β1x)P(y=1|x) = \frac{1}{1+e^{-(β_0+β_1x)}}P(y=1∣x)=1+e−(β0+β1x)1 - Naive Bayes
Based on Bayes’ Theorem:
P(A∣B)=P(B∣A)⋅P(A)P(B)P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)}P(A∣B)=P(B)P(B∣A)⋅P(A) - Decision Trees
Splits data using entropy or Gini index. - Support Vector Machine (SVM)
Finds the hyperplane that maximizes margin between classes. - K-Nearest Neighbors (KNN)
Classifies based on majority vote of nearest neighbors.
Clustering Algorithms
- K-Means Clustering
Objective: Minimize within-cluster variance. - Hierarchical Clustering
Builds a tree-like structure of clusters.
Ensemble Methods
- Random Forest – Combines multiple decision trees.
- Gradient Boosting – Sequentially corrects weak learners.
- XGBoost – Highly efficient gradient boosting method.
Important Metrics in Machine Learning
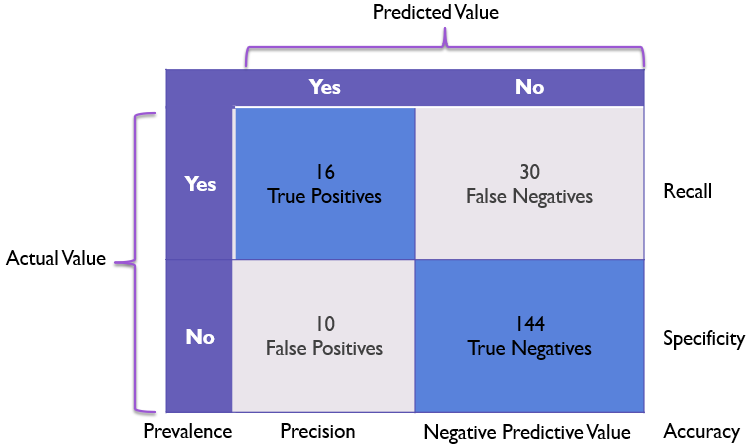
For Classification
- Accuracy:
Accuracy=TP+TNTP+TN+FP+FNAccuracy = \frac{TP + TN}{TP + TN + FP + FN}Accuracy=TP+TN+FP+FNTP+TN - Precision:
Precision=TPTP+FPPrecision = \frac{TP}{TP + FP}Precision=TP+FPTP - Recall (Sensitivity):
Recall=TPTP+FNRecall = \frac{TP}{TP + FN}Recall=TP+FNTP - F1 Score:
F1=2×Precision⋅RecallPrecision+RecallF1 = 2 \times \frac{Precision \cdot Recall}{Precision + Recall}F1=2×Precision+RecallPrecision⋅Recall - ROC Curve & AUC: Measure classifier performance.
For Regression
- Mean Squared Error (MSE):
MSE=1n∑(yi−y^i)2MSE = \frac{1}{n} \sum (y_i – \hat{y}_i)^2MSE=n1∑(yi−y^i)2 - Root Mean Squared Error (RMSE):
RMSE=MSERMSE = \sqrt{MSE}RMSE=MSE - Mean Absolute Error (MAE):
MAE=1n∑∣yi−y^i∣MAE = \frac{1}{n} \sum |y_i – \hat{y}_i|MAE=n1∑∣yi−y^i∣ - R² (Coefficient of Determination):
Measures proportion of variance explained by the model.
Mathematical Foundations & Formulas
Linear Algebra in ML
- Vector Dot Product:
a⋅b=∑aibia \cdot b = \sum a_i b_ia⋅b=∑aibi - Matrix Multiplication:
C=A×BC = A \times BC=A×B
Probability & Statistics
- Expectation:
E[X]=∑xiP(xi)E[X] = \sum x_i P(x_i)E[X]=∑xiP(xi) - Variance:
Var(X)=E[X2]−(E[X])2Var(X) = E[X^2] – (E[X])^2Var(X)=E[X2]−(E[X])2
Optimization in ML
- Gradient Descent Update Rule:
θ=θ−α⋅∇J(θ)θ = θ – α \cdot \nabla J(θ)θ=θ−α⋅∇J(θ)
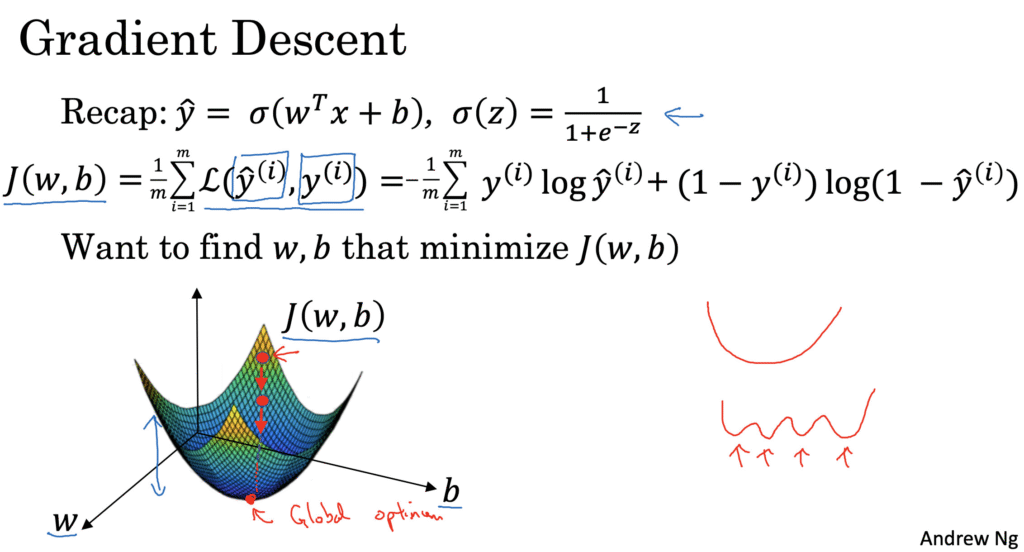
Quick Comparison Table: Algorithms & Use-Cases
| Algorithm | Type | Best For | Example Use Case |
|---|---|---|---|
| Linear Regression | Supervised (Regression) | Predict continuous values | House price prediction |
| Logistic Regression | Supervised (Classification) | Binary classification | Spam detection |
| Decision Tree | Supervised | Classification & Regression | Loan approval |
| K-Means | Unsupervised | Clustering | Customer segmentation |
| Random Forest | Ensemble | High accuracy, low overfitting | Fraud detection |
| SVM | Supervised | High-dimensional classification | Face recognition |
Machine Learning Formulas at a Glance
- Bayes’ Theorem:
P(A∣B)=P(B∣A)⋅P(A)P(B)P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)}P(A∣B)=P(B)P(B∣A)⋅P(A) - Entropy (Decision Tree):
H(S)=−∑pilog2(pi)H(S) = -\sum p_i \log_2(p_i)H(S)=−∑pilog2(pi) - Gini Index:
Gini=1−∑pi2Gini = 1 – \sum p_i^2Gini=1−∑pi2 - Gradient Descent:
θ=θ−α⋅∇J(θ)θ = θ – α \cdot \nabla J(θ)θ=θ−α⋅∇J(θ) - Cosine Similarity:
Cosine=A⋅B∣∣A∣∣⋅∣∣B∣∣Cosine = \frac{A \cdot B}{||A|| \cdot ||B||}Cosine=∣∣A∣∣⋅∣∣B∣∣A⋅B
FAQs
1. What is the difference between supervised and unsupervised learning?
Supervised learning uses labeled data to train models, while unsupervised learning finds hidden patterns in unlabeled data.
2. Which algorithm is best for classification tasks?
Logistic Regression, Decision Trees, Random Forests, and SVM are commonly used for classification tasks depending on dataset size and complexity.
3. Why are evaluation metrics important in ML?
Metrics like accuracy, precision, recall, and F1-score help determine how well a model performs on unseen data.
4. What is overfitting in machine learning?
Overfitting occurs when a model performs well on training data but poorly on test data because it memorized patterns instead of generalizing.
5. How do I quickly revise ML formulas for exams?
Use a cheatsheet with key formulas: Bayes’ theorem, entropy, gradient descent, error metrics (MSE, RMSE, MAE), and classification metrics.
Conclusion
Machine Learning is a vast subject, but with the right cheatsheet covering algorithms, metrics, and formulas, you can revise quickly and perform better in exams and placements. This guide provides exactly that—concise notes designed for BTech students and anyone looking for fast, structured revision.
Whether you’re learning for the first time or preparing for last-minute exams, keep this machine learning cheatsheet handy to master the essentials.
Author Profile
- At Learners View, we're passionate about helping learners make informed decisions. Our team dives deep into online course platforms and individual courses to bring you honest, detailed reviews. Whether you're a beginner or a lifelong learner, our insights aim to guide you toward the best educational resources available online.
Latest entries
 UncategorizedOctober 3, 2025AKTU BTech Important Questions & Notes
UncategorizedOctober 3, 2025AKTU BTech Important Questions & Notes Exam Revision NotesSeptember 24, 2025C++ Programming Cheatsheet – STL, OOP Concepts, Syntax
Exam Revision NotesSeptember 24, 2025C++ Programming Cheatsheet – STL, OOP Concepts, Syntax Exam Revision NotesSeptember 22, 2025Java Programming Cheatsheet – Collections, OOP, Exceptions
Exam Revision NotesSeptember 22, 2025Java Programming Cheatsheet – Collections, OOP, Exceptions UncategorizedAugust 28, 2025BTech 1st Year Notes & Cheatsheets (Subject-Wise)
UncategorizedAugust 28, 2025BTech 1st Year Notes & Cheatsheets (Subject-Wise)






